논문 제목 : Distilling Knowledge via Knowledge Review
컨퍼런스 : 2021 CVPR
저자 : Pengguang Chen et al
대학 : The Chinese Univ. of HongKong
영단어
- negligible : 너무 작아서 신경쓰지 않아도될 것
- intriguingly : interestingly 와 같은 의미로 흥미롭게도
- consecutive : 연속적인
초록
- 지금까지는 feature transformation 및 loss function에 초점을 맞췄다면, 본 논문은 connection path cross levels의 factor에 대해 연구하려고 함.
- KD의 첫걸음으로 cross-stage connection path가 제안됨.
- 우리의 새로운 review 메커니즘은 효과적이고 구조적으로 단순함
- 우리의 최종 디자인된 nested, 컴팩트한 프레임워크는 거의 티 안나는 수준의 연산 오버헤드가 요구되며, 다른 method보다 좋은 성능을 보임
서론
- CNN 모델의 과한 연산량 이슈 및 메모리 소비 이슈때문에 제한된 자원을 가진 디바이스에 적용 가능성에 문제가 존재함
- 따라서, 빠른 학습 과 compact한 신경망 기술이 필요함
- 본 논문은 Teacher와 Student 사이의 connection path에 관한 새로운 관점에 문제 제기함
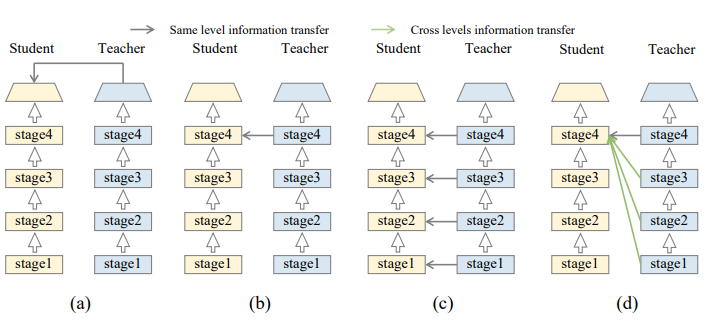
- 지금까지의 논문들은 같은 레벨의 information을 Student에 가이드 해주는 방식으로 connection path을 다룸.
- ex) Student의 4번째 output을 봤다면, Teacher도 4번째 stage의 output을 봐야함
- 이전까지는 connection path의 중요성을 무시해왔었다면, 논문은 핵심적인 수정으로 Teacher의 낮은 레벨의 feature를 사용해 Student의 깊은 feature를 지도함
- 깊은 feature는 큰 수용력을 지니고 있어 teacher의 low-level feature로부터의 유용한 정보를 학습할 수 있음
- 인간의 학습 커브 과정으로 보면, 배웠던 지식의 작은 부분을 어린아이가 겨우 이해하는데, 점점 자라면 자랄수록, 과거로부터의 더 많은 정보들은 점진적으로 경험처럼 이해되고, 기억된다는 과정을 보인 것임.
- 결국 Knowledge Review 라는게 과거의 작은 지식을 배우고, 점차적으로 더 많은 정보들을 배우면서 이를 복습처럼 학습하는 방식임.
- 유용한 multi-level 정보를 어떻게 추출해서 어떻게 Student에 전이시킬 수 있을지는 난제임.
- 논문은 학습 과정 안정화 및 효율성을 위해 Residual Learning 프레임워크를 제안. 더불어, 새로운 Attention based fusion(ABF) 모듈과 Hierarchical Context Loss(HCL) 함수로 성능을 증진시킴.
본론
- input image X, Student Network S가 주어질때, 최종 Student의 출력 logit은 다음과 같음
$$ \mathbf{Y_s} = \mathcal{S}(\mathbf{X}) $$
- 여기서, single-layer KD를 표현하게 되면 다음과 같음
$$ \mathcal{L_{\mathbf{SKD}}} = \mathcal{D}(\mathcal{M}_s^i(\mathbf{F_s^i}), \mathcal{M}_t^i(\mathbf{F_t^i})) $$
- 여기서는, 하나의 layer에 대한 Student와 Teacher의 Feature의 Transformation한 형태의 Distance Metric을 적용
- 확장해서 Multi-layer KD는 각 layer마다의 Distance를 합산하는 과정은 아래와 같음
$$ \mathcal{L_{\mathbf{MKD}}} = \sum_{i\in \mathbf{I}}\mathcal{D}(\mathcal{M}_s^i(\mathbf{F_s^i}), \mathcal{M}_t^i(\mathbf{F_t^i})) $$
- 논문에서 제안하는 Review mechanism은 이전의 feature를 통해 current feature를 가이드하는 방식임
- Review Mechanism을 multi-layer KD에 적용하여 표현한 수식은 다음과 같음
$$ \mathcal{L_{\mathbf{MKD\R}}} = \sum{i\in \mathbf{I}}(\sum^i_{j=1}\mathcal{D}(\mathcal{M}_s^{i,j}(\mathbf{F_s^i}), \mathcal{M}_t^{j, i}(\mathbf{F_t^j}))) $$
- 결국, Student 의 첫번째 layer에 대해서는 Teacher의 첫번째 layer, 두번째 layer에 대해서는 Teacher의 첫번째, 두번째 layer와.. 등으로 연산이 이루어짐
- 위와 같은 손실함수는 기존의 손실 함수들과 함께 단순히 추가되어 사용된 것임. 즉, 학습 과정에서만 추가 비용을 들이고, 실제 사용시에는 기존 모델과 동일한 수준의 계산 비용으로 운영될 수 있음
- 결국, 학습 시에는 새로운 손실 함수를 추가하여 모델의 성능을 개선할 수 있지만, inference(테스트 과정) 시에는 추가적인 비용 없이 원래 모델과 같은 방식으로 작동
$$ \mathcal{L} =\mathcal{L_\mathbf{CE}} + \lambda\mathcal{L_{\mathbf{MKD\_R}}} $$
3.2 Residual Learning Framework


(a)
- 처음 디자인한 위와 같은 구조는 Student의 Transformation 함수를 Conv 와 nearest interpolation layers로 변환하여 Teacher와 크기를 매핑 시켰음.
- 이때, Teacher는 변환되지 않음.
(b)
$$ \mathcal{L_{\mathbf{MKD\R}}} = \sum{i\in \mathbf{I}}(\sum^i_{j=1}\mathcal{D}(\mathcal{M}_s^{i,j}(\mathbf{F_s^i}), \mathcal{M}_t^{j, i}(\mathbf{F_t^j}))) $$
- (b). 그림은 위와 같은 수식으로 구성된 것을 표현한 것임
- 단순히, 모든 stage에서의 feature를 증류시킨 것으로 확인할 수 있음
- 하지만, 이러한 방식은 stage 사이의 거대한 정보가 포함됨에 따라 최적화된 방식이라고 할 수 없음
- 학습 단계동안 stage의 모든 feature를 사용한다는 것에 대한 복잡성을 야기함
- 위 그림만 봐도 4개의 stage로 구성된 모델은 총 4 * 5 / 2 로 10개 feature를 loss function이 감당해야하는데, 이보다 많아지면 그만큼 복잡성은 더욱 증가하는 구조임
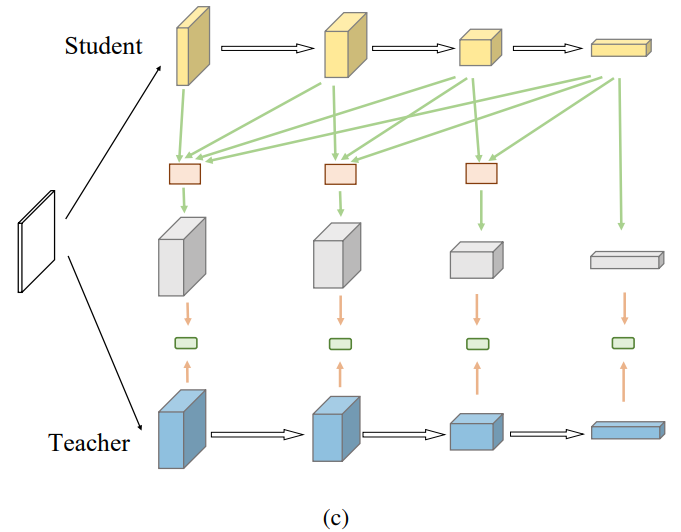
(c)
- (b).에서 모든 stage별 feature를 감당해야하는 복잡성을 줄이기 위해, 논문은 L_MKD_R의 loss function의 간소화를 수행함.
$$ \mathcal{L_{\mathbf{MKD\R}}} = \sum^n{j=1} (\sum^n_{i=j}\mathcal{D}(\mathbf{F}^i_s , \mathbf{F}^j_t )) $$
- 먼저, Feature Transformation function M을 생략하여 위와 같이 표현하며, 여기서 summation j=1 → n 의 소괄호 내 포함된 수식은 아래와 같이 표현한다고 함.
$$ \sum^n_{i=j}\mathcal{D}(\mathbf{F}^i_s , \mathbf{F}^j_t )\approx \mathcal{D}(\mathcal{U}(\mathbf{F}^j_s, \cdots, \mathbf{F}^n_s), \mathbf{F}^j_t) $$
- U는 (b)에서 처럼 표현된 stage별 feature들을 fusion할 수 있는 fuse feature 모듈임.
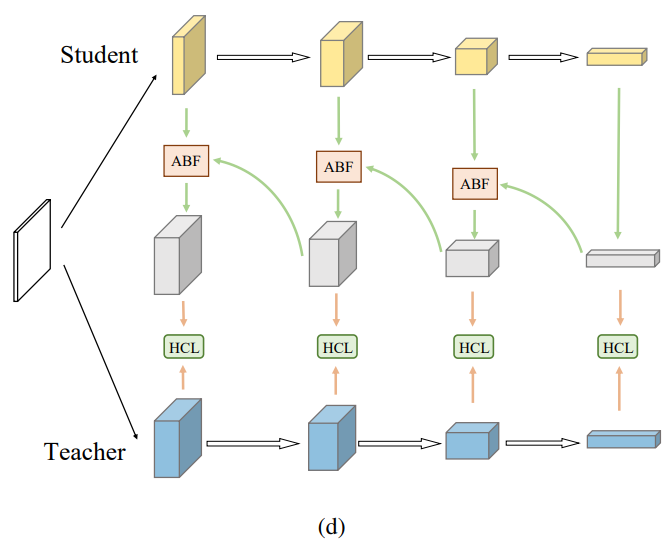
(d)
- (c). 구조에 대해 더욱 간소화를 위해 재귀적으로 distillation 진행할 수 있는 구조를 위의 그림처럼 표현함.
- 여기서 ABF와 HCL을 통해 효율적인 Knowledge Review 구조를 만들고자 하였음
ABF and HCL
- (d). 그림을 보다시피 핵심적인 2가지 구성요소가 존재함.

- ABF(Attention based Fusion) Process
- 더 높은 레벨의 feature가 낮은 레벨의 feature와 같아지도록 resize 수행
- 이후, 다른 레벨의 2개의 feature는 concatenate되어 2개의 H x W attention map을 생성.
- 이 map들은 2개의 feature와 제각각 곱해짐.
- 마지막으로,2개의 feature는 더해져서 최종 output을 생성함
- 이러한 ABF 모듈은 input feature에 따라 다른 attention map을 생성함. 따라서, 2개의 feature map은 동적으로 합산될 수 있다. 이러한 적응형 합산 과정은 2개의 feature map이 다른 stage에서 올 뿐더러 정보가 다양함에 따라 직접적인 합산 과정보다 더 좋다고 한다.
- attention mechanism 자체가 같은 것을 보더라도 서로 다른 수준에서 attention 하자는 의도인데, 이처럼 low와 high 레벨 feature는 서로 다른 부분에서 집중될 수 있음
- HCL(hierarchical context loss) Process
- 2개의 feature map 사이에서 주로 L2 distance를 활용하는게 흔함
- L2 distance는 같은 레벨로부터의 feature의 정보를 전이하는데 효과적임
- 하지만, 본 논문의 프레임워크는 다른 레벨의 정보를 합산하는 과정임에 따라 기존의 L2 distance를 활용하기에는 좋지않다고 함
- Pyramid scene parsing network에 영감을 받아, spatial pyramid pooling을 활용하고자 함.
- Spatial pyramid pooling을 사용한 다른 레벨의 지식을 추출
- 이후, 다른 레벨로부터의 feature를 제각각 L2 distance를 진행함
Results
- Image Classification, Object Detection, Instance segmentation task에서 outperform한 성능을 보였음
More Analysis
Knowledge Distillation across Stages
- Stage cross KD에 대한 성능을 분석하기 위해, ResNet20을 Student로 쓰고, ResNet56을 Teacher로 삼아 Cifar-100 데이터셋에 대한 성능을 확인함.
- 두 모델은 4개의 stage로 이루어짐.
- 실험 결과, Teacher의 낮은 stage의 정보는 Student의 학습에 도움이 됨을 알 수 있었음.
- 더불어, 같은 Stage의 정보는 좋은 성능을 보였다는 것도 알 수 있었음
- 이러한 현상은 Student의 더 깊은 stage는 Teacher의 더 낮은 stage로부터의 정보를 더 잘 배울 수 있었음.
- 또한, Student의 낮은 Stage에서는 Teacher의 Deep한 Stage에 대해 좋지 못한 성능을 보인 것은 너무 복잡하고 추상적인 정보가 복잡하게 만들었다는 것을 알 수 있음
'논문 리뷰' 카테고리의 다른 글
| Class-aware Information for Logit-based Knowledge Distillation 논문 리뷰 (5) | 2024.03.08 |
|---|---|
| Decoupled Knowledge Distillation 논문 리뷰 (0) | 2024.02.23 |
| GCN paper review (0) | 2023.06.02 |
| GCN paper review 전 공부 - semi-supervised learning (0) | 2023.05.30 |
| MobileNet paper review (0) | 2023.02.08 |