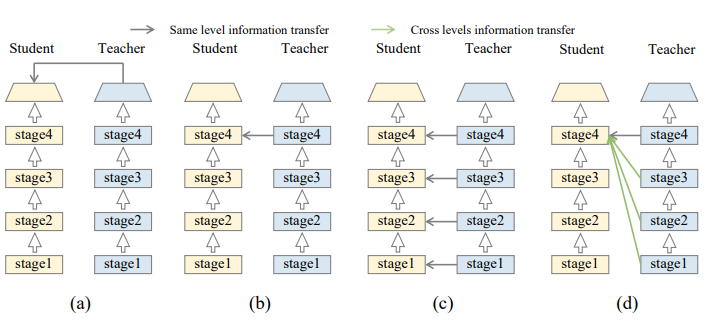
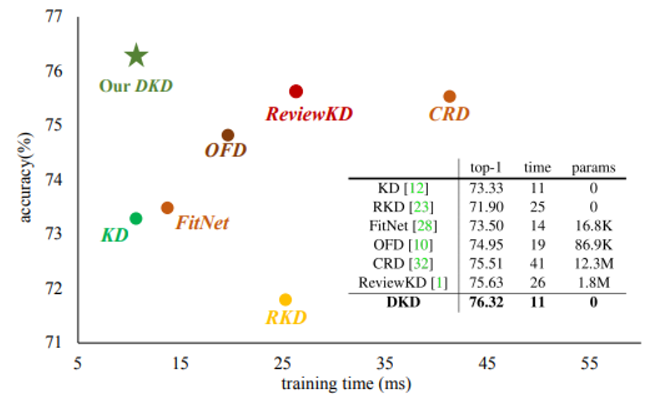
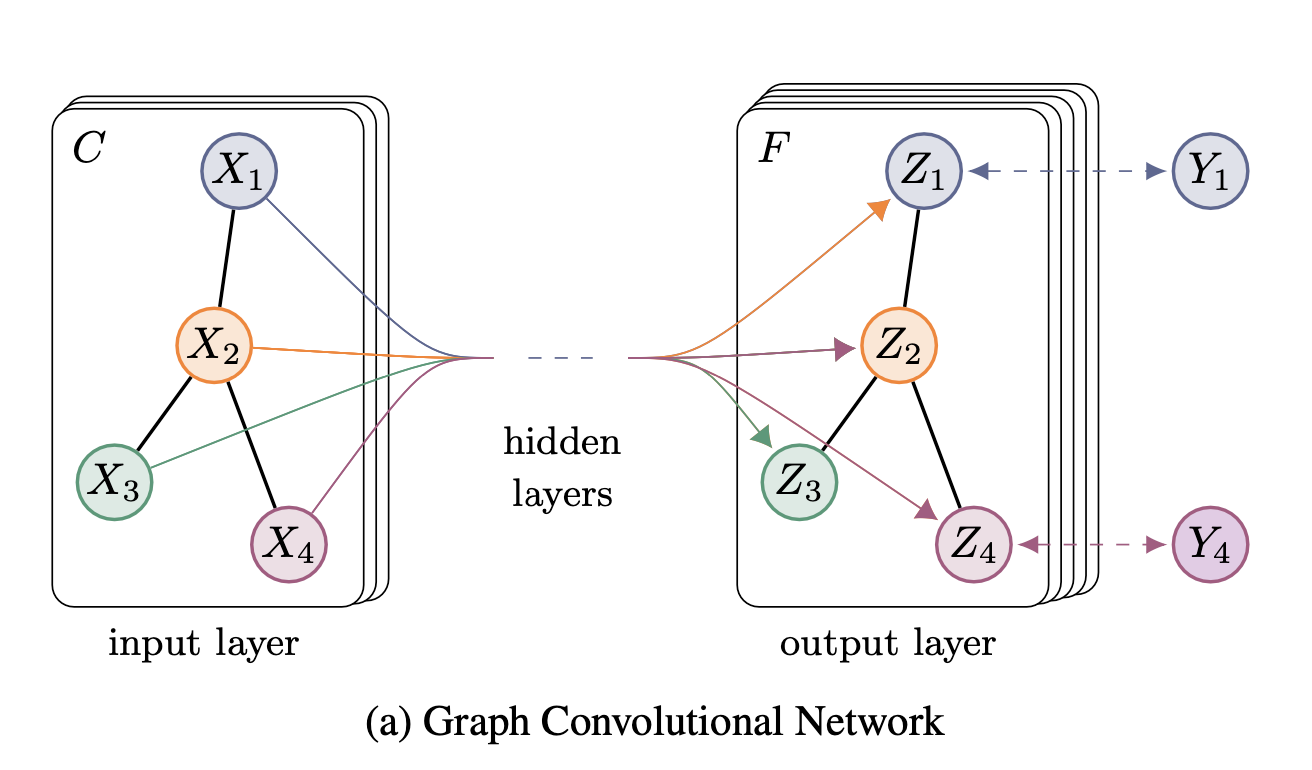
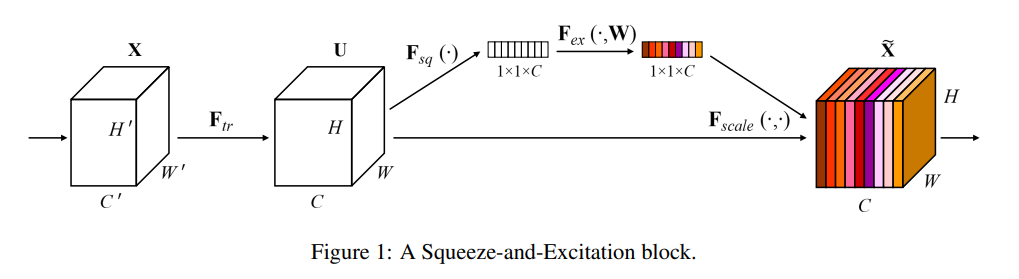
논문 제목 : Class-aware Information for Logit-based Knowledge Distillation 컨퍼런스 : ?? 저자 : Shuoxi Zhang, Hanpeng Liu 대학 : School of Computer Science and Technology Wuhan 초록 지금까지의 logit-based distillation은 instance level에서 다루었다면, 논문은 다른 의미적인 정보들을 간과했던 것들을 관찰해보려고함 논문은 간과점 문제를 다루기 위해 Class aware Logit KD(CLKD)를 제안함. 이는 instance-level과 class-level을 동시에 logit distillation하기 위한 모듈임 CLKD는 distillation perfo..