※이해가 잘 안 되는 부분들 미리 정리.
딥러닝에서 -wise라는 용어가 자주 언급됨.
-wise : ~별로 따로따로 나눠서 뭔가를 수행한다. ~에 따라 뭔가를 수행한다.
ex)
depth-wise convolution : feature map 뭉치를 채널별로 따로따로 나눠 각각을 특정 커널에 통과.
channel-wise concatenation : 여러 feature map 뭉치를 채널에 따라 feature map을 쌓는다(일반적인 딥러닝 concat을 의미)
point-wise convolution : feature map의 픽셀 포인트별로 따로따로 나눠서 각각을 특정 커널에 통과.
spatial-wise attention : feature map 뭉치를 하나하나 떼서, 즉 공간 별로 따로따로 나눠서 각각에 대한 attention 계산 수행.
기존의 2차원 Convolution은 3가지의 문제점이 존재
- Expensive Cost, Dead Channel, Low Correlation between channels
또한 영상 내의 객체에 대한 정확한 판단을 위해서 Contextual information이 중요함. 가령, 객체 주변의 배경은 어떠한 환경인지, 객체 주변의 다른 객체들은 어떤 종류인지 등. Object Detection, Object Segmentation에서는 충분한 Contextual information을 확보하기 위해 상대적으로 넓은 Receptive Field를 고려해야 한다.
일반적으로 CNN에서 Receptive Field를 확장하기 위해 Kernel Size Expansion, more and more stacked convolution layers를 생각할 수 있다. 다만, 두 방법은 모두 연산량을 크게 증가시키기에 부적절한 방법이 될 수 있음.
- Drop-in replacement
컴퓨터공학 등에서 서용되는 용어로 어떤 프로그램을 대체했을 때 다른 설정 등을 바꿀 필요가 없고 성능 저하도 없으며 오히려 속도, 안정성, 용량 등의 성능이 올라가는 대체를 의미.
Receptive Field(수용영역, 수용장)
receptive field는 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기를 뜻함.
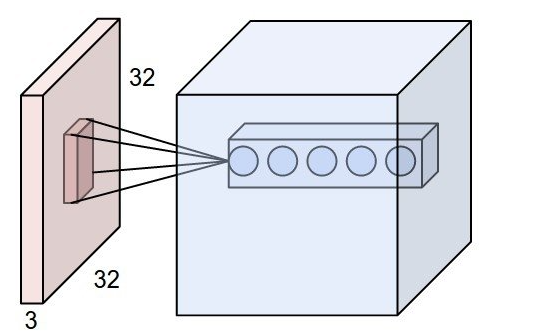
위 그림과 같이 입력이 32 * 32 * 3 인 경우 가중치(필터)의 크기가 [5 * 5 * 3]이라면 receptive field는 5 * 5* 3이 됨. 필터의 크기와 동일.
입력이 [16 * 16 * 20] 인 경우는 일반적인 convolution에서 하나의 필터의 크기는 [w * h * 20] 이 되어야 함.
이때의 receptive field는 w * h * 20임
이제부터 논문 리뷰 스타트!
1. Introduction
CNN은 다양한 visual tasks들을 다루는데 효과적인 모델이라는 것이 입증이 되었다.
각각의 Convolutional layers는 informative combinations(정보적인 결합)이 공간적 그리고 channel-wise 정보가 local receptive fields로 인해 이루어진다. 그리고 합성곱 층을 쌓음으로써 CNN은 전체적인 receptive field를 계층적 패턴과 함께 포착할 수 있어서 강력한 이미지 인식을 할 수 있었음
최근연구로는 GoogleNet에서 제안한 Inception 모듈(다형의 규모 프로세스 내장함)을 통해 좋은 성능을 냄.
본 논문은 네트워크의 표현력을 개선시키기 위해 Convolutional feature의 채널 간의 상호의존성을 명시적으로 모델링하는 목표로 SE Block을 제안함.
기본적인 구조는 Fig.1을 보면 된다.
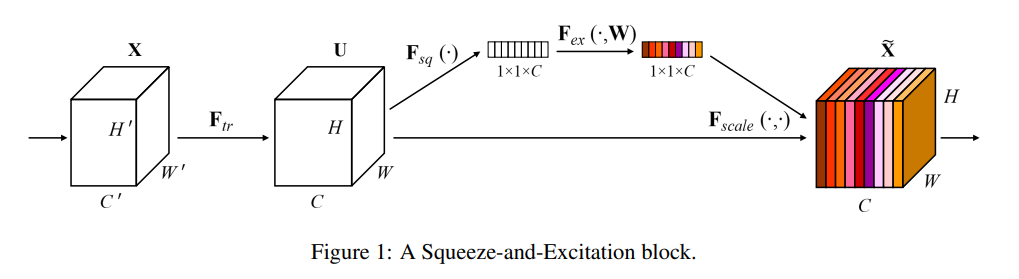
Feature맵 F는 feature recalibration을 위해 squeeze operation을 거치게 된다. 그러면 H * W의 channel로 압축이 이루어진다. 이 과정을 통해 나오는 H * W 은 channel-wise feature 즉, 채널별로 피쳐맵의 전체적인 분포를 내장할 수 있게 된다.
이후에는 excitation operation에서 각 채널마다의 피쳐맵 U가 가중치를 reweight 하게 된다.
이러한 SE network 구조는 drop-in replacement로 이용할 수 있기 때문에 기존의 모델의 어떠한 층에도 적용시킬 수 있다는 장점을 내세운다.
그리고 lower layers들에서 SE Block은 클래스 상관없이 중요한 특징을 추출하는 것에 대해 가속(bolstering) 시킬 수 있다는 장점과 함께 later layers들에서는 클래스와 관련 있는 특징들을 추출할 수 있다는 장점을 가지고 있다.
결과적으로 SE Block에 의해 수행되는 feature recalibration의 이점은 전체 network를 통해 누적(accumulated)될 수 있다.
2. Squeeze-and-Excitation Blocks
※ Related Works 생략(Deep architectures & Attention and gating mechanism)에 대한 내용임
위의 Fig.1에서 F_tr을 추출하기 위해서는 아래의 수식을 따른다.

v와 X가 곱해지는 연산은 convolution 연산을 의미.
output U는 모든 채널의 합계로 만들어진다. 그리고 v는 채널의 의존성을 명시적으로 내장되어 있다고 하였다. 이러한 의존성은 필터들에 의해 공간적인 상관관계가 얽혀있다고 해석하였다.
기존의 네트워크는 이러한 convolution 연산만 진행하고 그다음의 layer들로 넘어가지만, SENet은 네트워크가 정보 기능에 대한 민감도를 높이고, 덜 유용한 정보를 억누를 수 있도록 하고자 하였다.
이를 위해서는 two steps 과정이 필요한데, squeeze and excitation이다.
2.1 Squeeze : Global Information Embedding
채널 의존성에 다루기 위해 우리는 출력된 feature에서 각각의 채널의 signal을 고려해야 한다.
이러한 고려성은 현존하는 모델들의 feature map들의 맥락적 정보 이용 한정성 때문이다.
학습된 feature map들은 그 지역밖에서 맥락적인 정보로는 이용할 수가 없었다. 각각 다른 분야의 전문가들로부터 가져온 정보들이기 때문에 전체 맥락적으로 이용할 수 없으며, 정보 활용이 제한적이라는 의미이다.
결국 receptive field size가 더 작은 네트워크의 하위 계층에서 더욱 제한적이라는 문제 또한 발생한다.
이 문제를 해결하고자 하는 과정 중 첫 번째 Squeeze이다.
Squeeze는 앞서 구한 U(Feature map)을 압축하는 것을 목표로 한다.
여기서 받아온 Feature map U는 각각 학습된 필터들로부터 생성된 feature인데, 이를 먼저 Global Average Pooling을 통해 1 * 1 * C로 압축한다. (H * W * C -> 1 * 1 * C)

논문에서는 channel descriptor라고 지칭.
2.2 Excitation : Adaptive Recalibration
squeeze 한 정보를 전체 맥락적으로 이용하고자 Excitation 즉, 재보정 과정이 필요하다고 한다.
이 Excitation의 목표는 channel-wise 의존성을 포착하는 것이다.
이 Excitation은 두 가지 기준을 충족시켜야 한다고 한다.
- 유연해야 함 -> 채널 간 비선형 학습을 수용할 수 있어야 하기 때문
- 반드시 non-mutually-exclusive 관계를 학습해야 함 -> 다중 채널 강조를 위해
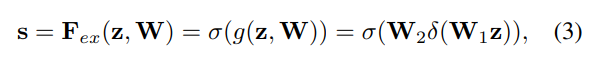
W1 * z를 통해 Fully Connected Layer를 거친다. 이때 노드 수를 C/r로 줄여주는 작업을 한다.
그리고 ReLU 활성화 함수를 거쳐 비선형 상태를 유지시켜 준다.
다시 Fully Connected Layer를 거쳐 C 노드 개수만큼 다시 출력되도록 하고, Sigmoid 함수를 통해 0~1의 값을 지닌 벡터로 출력시켜 준다.
여기서 질문이 있는데, 왜 굳이 C/r로 줄여줄까?
이는 채널 간에도 반드시 비선형성을 가해주는 것을 의도로 했다고 한다.
앞서 저자들의 주장이었던 Channel Relationship에 초점을 맞추기 위해 채널을 한번 reduction ratio r만큼 수축시킨 뒤, 비선형 함수 ReLU로 channel 간의 관계를 살핀 것이라고 한다.
수축시킨 벡터를 다시 C개로 출력하여 시그모이드로 0~1 값으로 Encoding 하여 feature map들을 모두 고려하여 중요도를 매긴 뒤, 최종적으로 이 확률 벡터들을 원래의 feature map U에 곱해준다.
결과적으로 보면, SE Block은 feature map U에서 어떤 채널에 주목해야 할지 focusing 해주는 역할을 해주었다고 생각하면 된다.
기존의 feature map들은 전부 독립적으로 바라보았지만, SE Block을 통해 C개의 채널들을 모두 고려하여 어떤 feature map이 얼마나 중요한지를 볼 수 있게 되었다.
예로 A와 B 간의 채널이 특정한 이미지 분류에 있어서 중요한 역할을 했다면 이 두 가지 채널은 최종 Sigmoid의 출력값을 높게 받을 수 있을 것이다. 이처럼 특정한 필터만 더 집중적으로 바라볼 수 있게 한 것이 SE Block의 최대 장점인 것이다.
이후의 Exemplars에서는 SE Block을 GoogleNet과 ResNet에 적용할 때의 내용

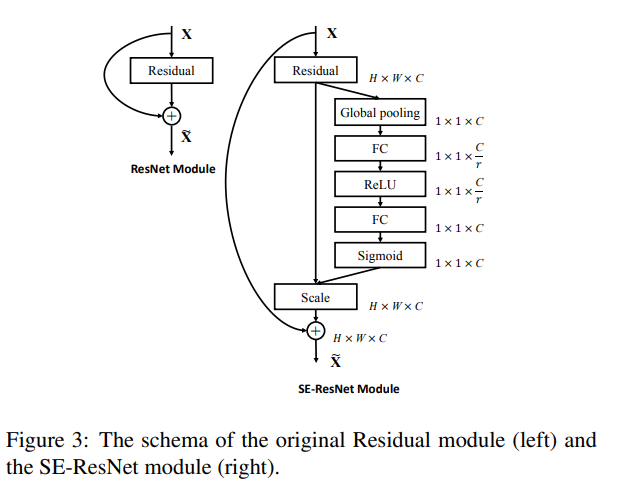
그리고 성능은 SE-ResNet 쪽이 더 좋았다고 함.
그리고 전반적으로 현존하는 모델들보다 SE Block을 적용한 모델의 성능이 더 좋았기도 함.
마지막으로는 Reduction Ratio r에 따라 성능 비교를 하였는데, 성능은 더 낮은 r일수록 높아졌다.
이는 파라미터 수가 r이 낮아질수록 증가함에 따라 당연하다고 생각한다.

결론은 SENet을 통해 유동적인 channel-wise feature 재보정을 하여 성능 향상을 하였다. 그리고, 이 SENet을 통해 기존 아키텍처의 channel-wise feature 의존성에 대한 한계점을 알 수 있었다.
'논문 리뷰' 카테고리의 다른 글
| Distilling Knowledge via Knowledge Review 논문 리뷰 (2) | 2024.02.29 |
|---|---|
| Decoupled Knowledge Distillation 논문 리뷰 (0) | 2024.02.23 |
| GCN paper review (0) | 2023.06.02 |
| GCN paper review 전 공부 - semi-supervised learning (0) | 2023.05.30 |
| MobileNet paper review (0) | 2023.02.08 |